Job Schedulers
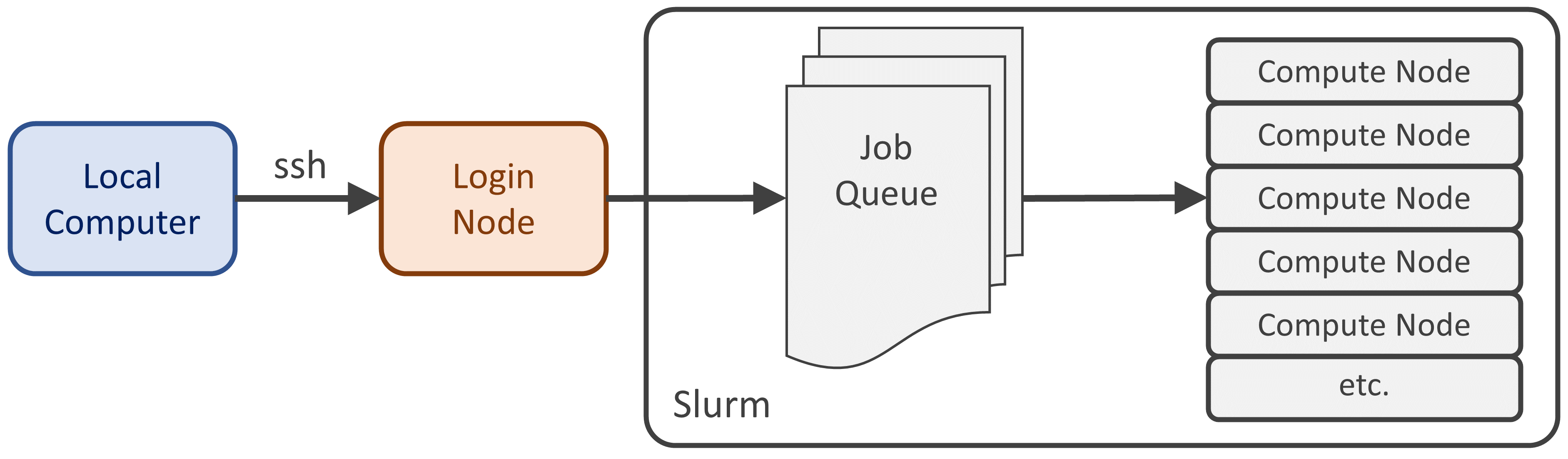
We used the term server cluster a couple of times now, as it describes most HPC resources like Great Lakes, which is not a single computer server, but a series of them networked together. Each individual computer is called a node. Server clusters might have hundreds to even thousands of nodes.
Use (and abuse) of the login node
Typically, you access the entire cluster from just one node, called the login node - the computer that accepts SSH connections.
The login node is a fully capable Linux server that can run any command. It is appropriate to use the login node to do tasks like:
- create and move files
- explore the contents of files
- do limited testing of commands and scripts
- monitor the status of the system
In general, if it takes less than a minute or two and/or limited compute power, go ahead and do it on the login node.
It is inappropriate to run complex, high-memory, long-running, CPU-intensive commands on the login node, because every other user is trying to use it to do simple tasks and you’ll get in their way. Great Lakes has usage monitors on the login node that will kill your command if it uses too much memory, etc.
Job schedulers: asynchronous access to other nodes
What you need is to tap into the large capacity of the other nodes in the cluster. This is done by making a request to use one or more of those nodes asyncronously, which means the command will only execute after some time has passed - perhaps only a few seconds, perhaps much longer if the cluster is busy and you have to wait in the job queue.
The program that handles your requests and decides which worker node will run your command, and when, is called a job scheduler. Great Lakes and many modern server clusters use Slurm as their chosen scheduler.
As always, Slurm is a program that takes inputs, has options, etc. Its primary input is a bash script specifying the work to run, its primary output is a job number, an integer that increments for every job queued on the server. You can use the job number to monitor the status of your work - whether it is waiting, running, failed or succeeded.
The MDI handles Slurm for you
As we will see later, the mdi command line utility knows how to talk to Slurm and does all that work for you! Therefore, we aren’t going to spend more time describing Slurm.
It is still a good idea to read about Slurm and its usage. UMich Advanced Research Computing (ARC) provides a comprehensive step-by-step guide:
https://arc.umich.edu/greatlakes/slurm-user-guide
One thing to learn about are interactive jobs - where you ask the job scheduler to bring up an interactive bash shell running on one of the worker nodes. Then you can run high-intensity work jobs at the command line with impunity since you are no longer on the login node.
Slurm accounts: paying for your usage
HPC resources aren’t cheap and you have to pay your way. You do this by getting a Slurm account. To be clear, this account is different than your user login. On Great Lakes, the Slurm account belongs to your principal investigator or project leader. You provide it to Slurm when you make your job request so the proper funding source can be applied.
If you haven’t already, now is the time to work with your supervisor to get permission to use a Slurm account: