assignSamples appStep module
The assignSamples appStep is the second step module of many apps. It recognizes that many apps will seek to support data analyses in which one or more replicate samples will be organized into groups for comparison, thus defining a structure of an experiment or project.
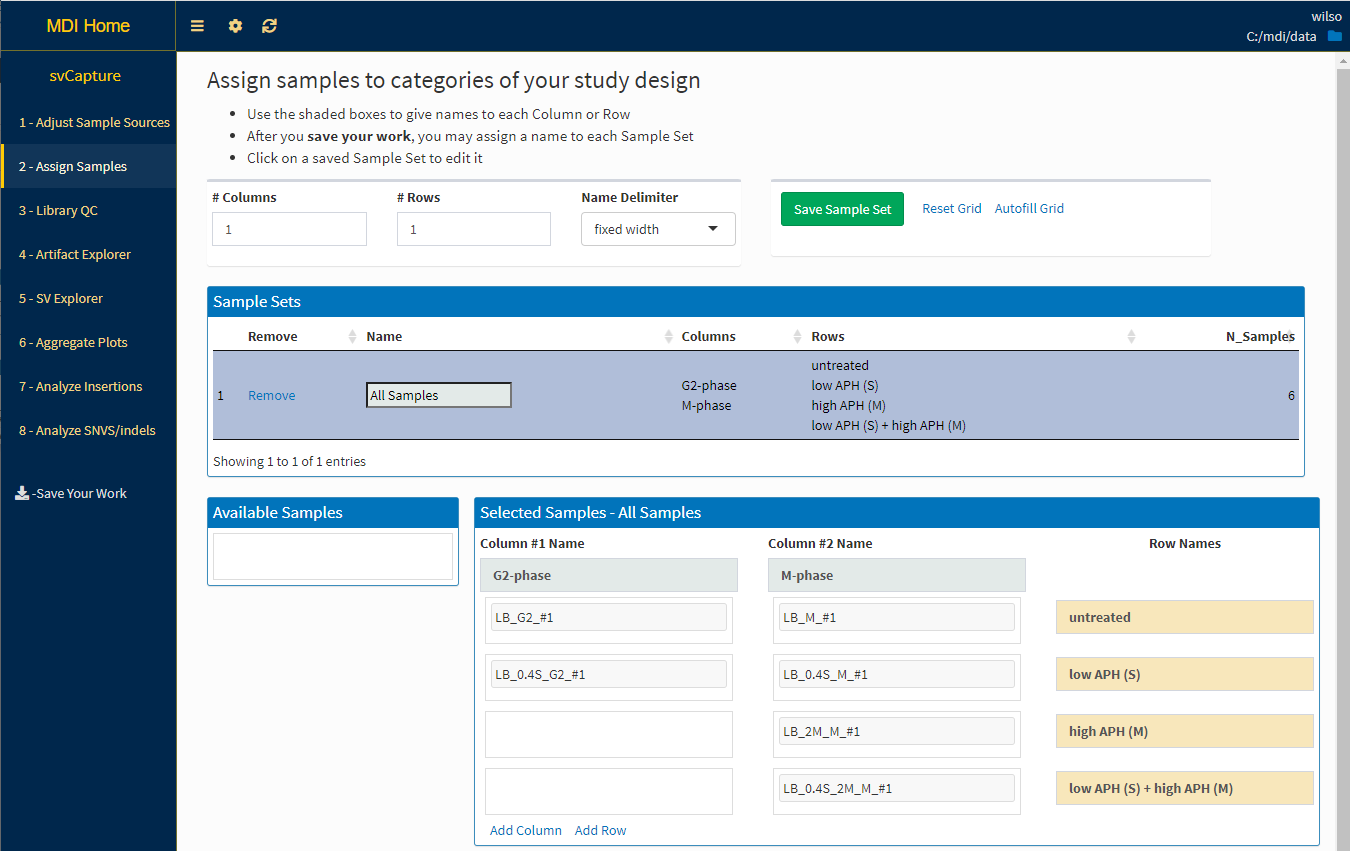
The assignSamples UI allows users to:
- create a grid representing the categories that define a Sample Set
- assign names to the categories
- assign replicate Samples into the cells of the grid, i.e., combinations of categories
- use various automation tools to auto-fill grids
- save multiple distinct Samples Sets from the same data sources
- edit previously saved Samples Sets when necessary, e.g., to remove bad Samples
For more detailed information, see:
Naming assignSamples steps
The canonical name given to assignSamples app steps is ‘assign’, which matches the step type declared in assignSamples/module.yml. We recommend following this convention as it promotes consistency and readability.
# <app>/config.yml
appSteps:
assign:
module: assignSamples
Step dependencies: sourceFileUpload or selectSamples
All apps that use the assignSamples module must also use either sourceFileUpload or selectSamples as their first step, as assignSamples reads its data from the structured outcomes, i.e. data sources and samples, of those steps.
Definition and structure of categories and sample sets
We use the term ‘sample set’ to refer to any combination of sample assignments into categories. We avoid the term ‘experiment’ or similar since the intent is that one experiment might yield many different sample sets to support different queries against the same data.
At present, assignSamples supports up to two categorical levels, shown as columns and rows of the grid. These are often referred to as groups and conditions, but can be named anything (see below).
Depending on the combination of an app’s restrictions and the user’s selections, a given sample set might have just one pot for collecting a single list of samples, or any number of groups and conditions.
Module options
The assignSamples appStep requires that <app>/config.yml declare the appropriate categories for downstream analysis steps, i.e., for the code that will use the assigned sample sets.
# <app>/config.yml
appSteps:
assign:
module: assignSamples
options:
categories:
<columnName>: # category level 1 = grid columns
singular: Example
plural: Examples
nLevels: 1:10
<rowName>: # category level 2 = grid rows
singular: Example
plural: Examples
nLevels: 1:10
Your app may choose to support zero, one, or two categorical levels. Simply omit a level if you don’t need it. Having no categories means that users will only be offered single-pot assignments.
The keys of the categorical levels are used to access values in code.
The user-friendly names shown in the app for the categorical levels are determined by the singular and plural keys.
The nLevels keys establish the app’s restrictions on the numbers of rows and columns it expects and can support. Including nLevels == 1 means that your app doesn’t require, but can support, a categorical level, e.g., it can support row x column as well as column-only grids. Setting nLevels:2 for both categories means your app only supports 2 x 2 grids, etc.
Returned outcomes
These are the outcomes returned by the assignSamples module that you may access in downstream appStep modules.
# assignSamples_server.R
list(
outcomes = list(
sampleSets = reactive(data$list),
sampleSetNames = reactive(data$names)
)
)
where:
- sampleSets = named list of the sample set assignments the user has saved (see below)
- sampleSetNames = named vector of the human-readable names the user gave to those sample sets; the names of sampleSetNames are the same as the names of sampleSets
The sampleSets reactive returns a list with members:
- nLevels = integer vector of the number of actual levels for two categories
- nSamples = the total number of assigned samples
- assignments = a data.frame of sample assignments (see below)
- name = a unique name for the sample set, not intended to be human-readable
- categoryNames = the names the user gave to the grid columns and rows (a list of two character vectors with lengths == nLevels)
The assignments data.frame has one row per assigned sample, with columns:
- Source_ID = the unique ID of the source data package. for data retrieval
- Project = the name of the project associated with Source_ID
- Sample_ID = the name of the sample
- Category1 = the index (1 or 2) of the first categorical assignment (i.e., the grid column)
- Category2 = the index (1 or 2) of the second categorical assignment (i.e., the grid row)
All members are present with values even if there is only one level, the category assignments will simply be set to 1.
The concatenation of Project and Sample_ID together is used to create a unique identifier for a sample, since Sample_ID might have been used repeatedly in different data sources.
Notice that each assigned sample will have exactly one row in the assignments data.frame, i.e., the assignSamples module supports the assignment of a sample to at most one grid position, since it rarely makes sense to compare a sample to itself. If there is a need to create multiple assignment pots that include the same sample, do that by creating multiple sample sets.
Many apps do not access those outcomes directly, favoring instead to use the following support utilities.
Support utilities
These are the utility functions provided by the assignSamples module to make it easier to get information about a sample sets and assignments.
# <scriptName>.R
# 'id' below is the name of a list entry in the sampleSets outcome
# get one or more user-assigned sample set names
sampleSetName <- getSampleSetName(id)
sampleSetNames <- getSampleSetNames(rows = TRUE) # rows of the assignments table
# get sample set information as a list keyed by user-assigned names
sampleSets <- getSampleSetsNamedList(rows = TRUE)
# get the app-defined names of the categories in use
# a list whose names are Category1... and values are the user-friendly names
# unless invert=TRUE, then names and values are flipped
categoryNames <- getCategoryNames(plural = FALSE, invert = FALSE)
# retrieve the assignments for a specific Sample Set as a data.table
# optionally, filter for matching categories
# if categoryNames == TRUE, add columns Category1Name and Category2Name with user names
assignments <- getSampleSetAssignments(id, category1 = NULL, category2 = NULL, categoryNames = TRUE)
# retrieve the display name of one assigned sample
# sample is a one row of the assignments() data.table we wish to match
sampleName <- getAssignedSampleName(sample)
For more detailed information, see:
mdi-apps-framework : assignSamples_utilities